Link to Kaggle competition page
Overview:
For my submissions, I developed one model using my own neural network and learning models entirely from scratch, and another one using the prebuilt neural network from Keras. I was able to use my custom model even as it grew in size and complexity, thanks to the good enough speed provided by Numpy arrays and matrix multiplication. However, when I needed to explore deeper into feature engineering and test different configurations of the neural network, my custom code became too slow to be practical. As a result, I switched to using a basic Keras neural network for my second submission.
At the end of this page I go into more detail about my custom code and the processes I went through while developing it. For my submission using TensorFlow and Keras, I trained a simple neural network that was about the same size as what I used for my custom code. However, this time, it was running approximately 1600 times faster. I tested various configurations output functions, number of layers, layer sizes, etc, as well as using different feature engineering approaches on the input data before finalizing my submission. No single configuration ended up being significantly better than the others, so difference between submissions created by my custom code and the Keras neural network ended up being pretty similar.
ESPN Tournament Challenge Finishes:
Men's Final Bracket Results:
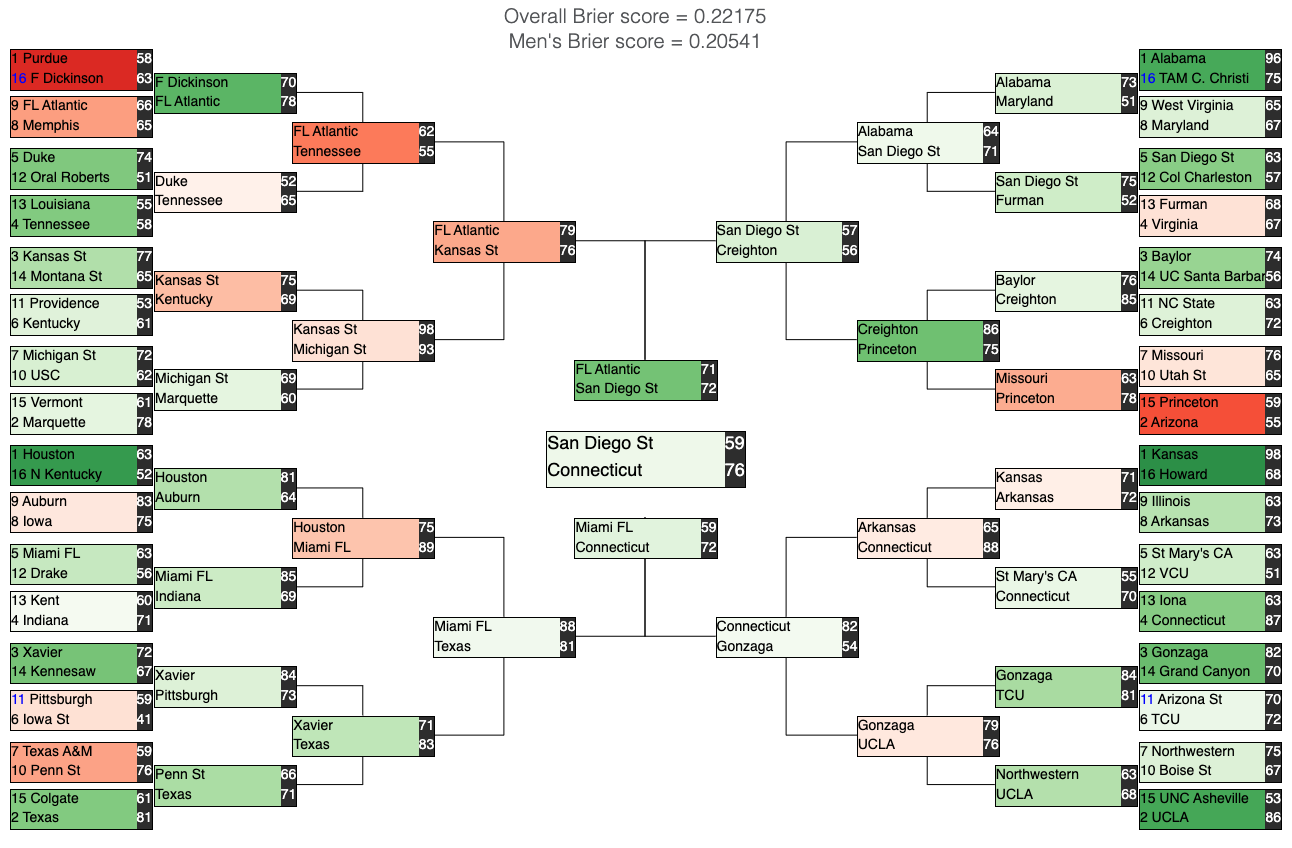
Women's Final Bracket Results:
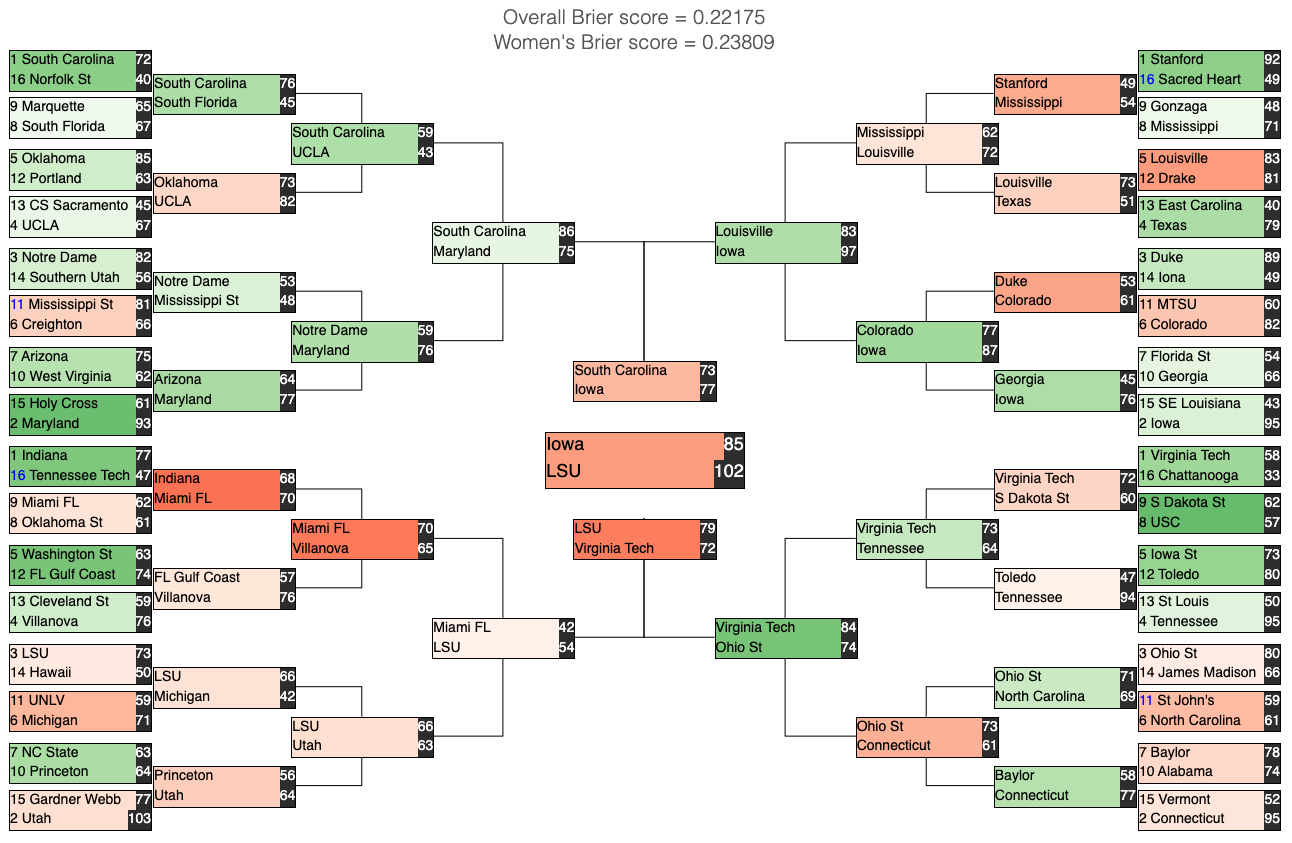
Thoughts after the end of the competition:
After the competition ended, I reflected on my performance and found that while I had a strong start and was even in the 11th spot at some point, I was ultimately disappointed with my final score. Two main takeaways emerged from the experience.
Firstly, I discovered a significant disparity in my code's performance between the Men's and Women's tournaments. This was due to my primary focus being on the Men's competition, which had a more detailed data set including the "Massy Ordinals" data. As a result, I developed a "strength of schedule" rating based on the seeding/ranking methods included in that data, which was useful for predicting outcomes in the Men's bracket. However, this data was not available for the Women's tournament, which lead to my code predicting many more upsets.
Secondly, I learned the importance of differentiating the way I trained my model and created my predictions. In retrospect, I realized that due to the scoring system and the nature of basketball as a sport, prioritizing the early rounds in my predictions would have led to better overall performance. As the tournament progresses, the matchups become increasingly harder to predict and the outputs trend closer to 50% confidence, leading to lower scores. For example, multiplying my Men's predictions from this year by a blanket factor like 1.1 or 1.2 already results in a net improvement. Therefore, I plan to further research and test this approach in future competitions.
More details about my approach using custom built neural network code:
I started with simple feature engineering to create input data from the final box scores of all the regular season games. Things like a teams average stats over their last 5 games, their opponents average stats, as well as more complex things like a teams stats in comparison to what their opponents usually give up (i.e. team A's opponents shoot 5% worse from 3 than they usually do when playing against team A; implying team A has good perimeter defense).
However, this approach still leaves a lot of factors unaccounted for. One in particular that interested me was how coaching might factor into a team's success and how to capture that with a neural network. After some research on possible options I decided to implement embeddings into my input layer starting with just an embedding for each team, and if that worked well then later I would add in embeddings for each coach as well.
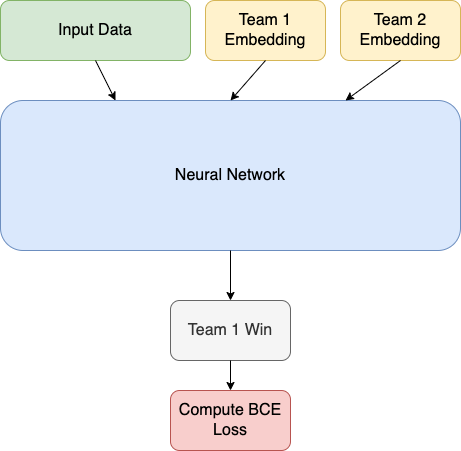
The actual network uses TanH for its activation functions and Binary Cross Entropy for its cost function and gradient descent. It uses a single output neuron, 1 or 0 representing whether or not team 1 will win.
To run it, the data initially provided by kaggle is run through my data_prep functions and outputs input data for the neural network with the proper formatting. This does all the work compiling the different team data from over the years, getting teams averages over their recent matches, as well as any of the other stats I might create. After this, I can run it through the training and testing code for whatever preset time period or number of steps that I want. The predicted solutions for men and women will be output into their own separate files and are ready for submission.
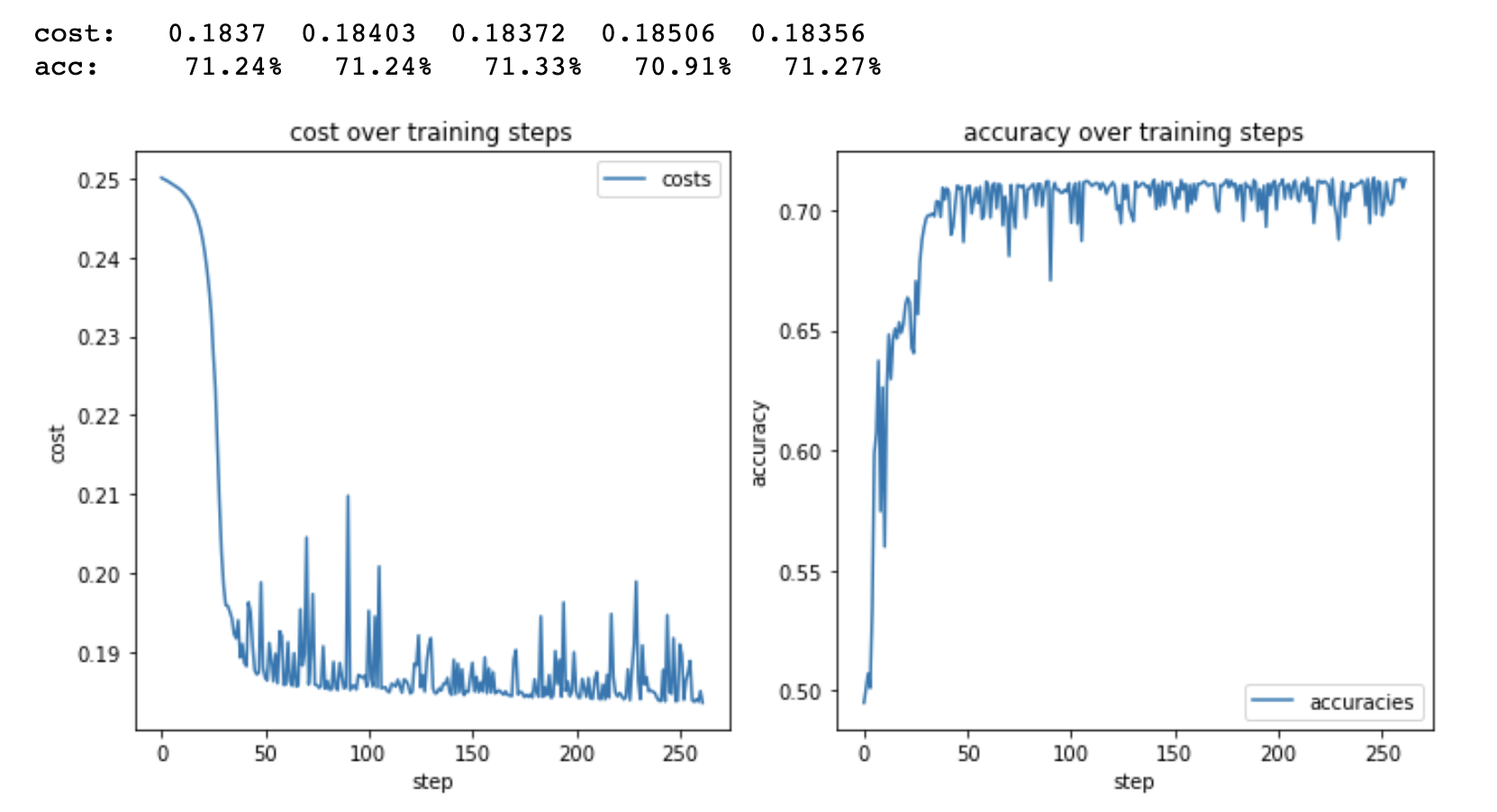
Despite the code and network functioning as intended, there were still many factors I was unsure about changing. Number of layers, neurons per layer, learning rate, what sets of input values to use, size of embeddings for both teams and coaches, learning rate for embeddings, and more.
For example, even if I wanted to test just three options for each one of these factors:
- learning rate - [0.01, 0.001, 0.0001]
- embedding size - [50, 75, 100]
- neurons per layer - [1, 1.5, 2]
- layers - [1,2,3]
In the context of the march madness competition, the training and running time of the network isn't really that important as it only has to make the final submission predictions once. In general, having the lower end of any of these values probably won't ever improve the cost or accuracy of the network, but it does help a lot with keeping training times down.
For my final submission I just went with the idea that I would use the more time-costly values for most of these while trying to keep things running fast while I was still tweaking things. This means more layers, more neurons, a slower learning rate, and bigger embeddings.
Thanks for reading!